DFS (Depth First Search)
맹목적 탐색방법의 하나로 탐색트리의 최근에 첨가된 노드를 선택하고, 이 노드에 적용 가능한 동작자 중 하나를 적용하여 트리에 다음 수준(level)의 한 개의 자식노드를 첨가하며, 첨가된 자식 노드가 목표노드일 때까지 앞의 자식 노드의 첨가 과정을 반복해 가는 방식이다. -출처 위키
여기서 "맹목적 탐색" 이라는 단어가 쓰인 이유는 연결된 노드 중 임의의 하나를 선택하여 탐색을 진행하는 방법이기 때문이다.
따라서 순서 복잡하게 여러 갈래가 될 수 있음
DFS의 장점
-
단지 현 경로상의 노드들만을 기억하면 되므로 저장공간의 수요가 비교적 적다.
-
목표노드가 깊은 단계에 있을 경우 해를 빨리 구할 수 있다.
DFS의 단점
-
해가 없는 경로에 깊이 빠질 가능성이 있다. 따라서 실제의 경우 미리 지정한 임의의 깊이까지만 탐색하고 목표노드를 발견하지 못하면 다음의 경로를 따라 탐색하는 방법이 유용할 수 있다.
-
얻어진 해가 최단 경로가 된다는 보장이 없다. 이는 목표에 이르는 경로가 다수인 문제에 대해 깊이우선 탐색은 해에 다다르면 탐색을 끝내버리므로, 이때 얻어진 해는 최적이 아닐 수 있다는 의미이다.
위키에서 긁어 온 장단점이다. 조금만 원리를 생각해보면 이해가 가능하나, 실제 알고리즘 문제를 풀어보면서 체감하는 것이 중요할 것 같다.
오늘은 간단히 재귀함수로 preorder, inorder, postorder 세 가지 방법으로 이진 트리 노드를 출력하는 것을 공부했다.
DFS 공부라기보다는 stack+recursive+tree 순회의 기초 공부라고 할 수 있겠다.
#include <stdio.h>
using namespace std;
void D(int v){
if(v>7) return;
else{
//전위순회 print 위치
printf("%d", v);
D(v*2);
//중위순회 print 위치
D(v*2+1);
//후위순회 print 위치
}
}
int main(){
D(1);
return 0;
}
프로그램이 실행되고 함수가 호출되면, 스택에 함수에 대한 값이 저장된다. 저장되는 값은 크게 세 가지가 있다.
지역변수, 함수의 인자, 복귀 주소
재귀함수는 이를 이용하여 반복적인 호출로 실행되는 함수이며, return을 만난 후에는 부모 함수의 복귀 주소 위치로 돌아간다.
stack이기 때문에 return 이후에는 pop 으로 저장 값이 삭제되는 구조이다
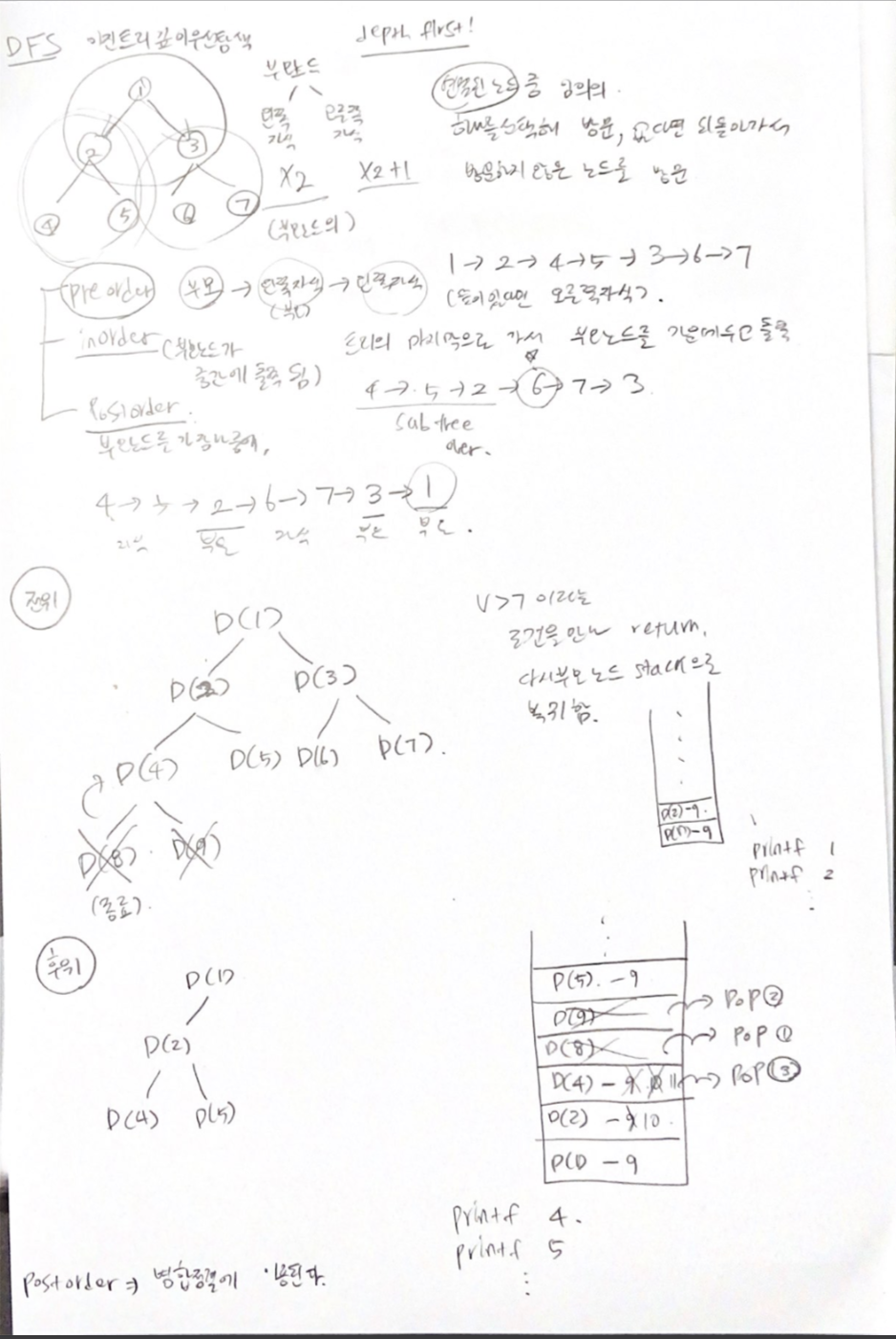
강의 들으며 메모한 내용..
더 깊은 공부를 하러 가겟슴!!
'Algorithms > C++' 카테고리의 다른 글
| C++/ 우선순위 큐 + 구조체를 이용한 벡터 정렬 (3개 이상의 값) (1) | 2021.02.06 |
|---|---|
| C++/ DFS 완전탐색 -이중배열, STL vector pair (0) | 2021.01.30 |
| C++/ Queue 자료구조 정리 (0) | 2020.12.26 |
| C++/ Stack 자료구조 정리 (0) | 2020.12.26 |
| C++/공주구하기 + 조세퍼스 (0) | 2020.12.14 |

